

Marina Giardinetti a été recrutée pour travailler sur le projet EyCon dont l’objectif est d’explorer les possibilités de visualisation, de navigation et d’analyse de grands corpus visuels, perspectives nouvelles ouvertes par le recours à l’intelligence artificielle. Il est mené par Lise Jaillant (Université de Loughborough, Royaume-Uni) et Julien Schuh (Université Paris Nanterre) soutenus par le Labex Passés dans le Présent et l’Arts and Humanities Research Council, ainsi que par Daniel Foliard (LARCA) dans le cadre de sa chaire Idex-Université de Paris. Marina revient sur son parcours, l’apport des Humanités Numériques et la spécificité du travail sur l’intelligence artificielle et la structuration des données.
Quel est ton parcours et ce qui t’a amené sur ton domaine actuel d’expertise ?
J’ai été rapidement intéressée par la recherche dès mes premières années d’études supérieures, ce qui m’a d’abord mené à achever un master de recherche d’histoire à l’université Paris 7. Mes sujets de recherche étaient l’histoire de l’éducation artistique des jeunes filles en Angleterre au XVIIIe siècle, notamment à travers des dessins techniques à visée industrielle (j’ai publié un article à ce sujet, voir: https://journals.openedition.org/artefact/10299) . J’ai découvert rapidement les Humanités numériques dans lesquelles j’ai souhaité me spécialiser, j’ai effectué un deuxième master à l’Ecole Nationale des Chartes avec les mêmes thématiques de recherche (des manuels de dessin anglais pour filles et garçons, le rapport entre les images et le texte), ce qui me permet maintenant de développer des outils pour des projets en humanités numériques.
Sur quels projets as-tu travaillé avant Ey-Con ?
J’ai travaillé comme ingénieure de recherche au sein du projet BaOIA (https://baoia.huma-num.fr/) dans lequel j’ai pu développer des outils et tutoriels d’intelligence artificielle pour chercheur.euse.s en humanités souhaitant se familiariser avec des solutions numériques. J’ai effectué ce projet à La Contemporaine (Nanterre) et travaillé sur leur corpus, ainsi que ceux de la BNF et d’autres bibliothèques numériques. Les outils et tutoriels sont disponibles et les codes open source, quelques résultats ont été publiés (voir https://bnf.hypotheses.org/11405, https://modoap.huma-num.fr/romans_scolaires/).
Le projet BaOIA (Boîte à Outils d’Intelligence Artificielle) s’inscrit dans les projets de numérisation de masse des institutions patrimoniales et vise à créer un panel d’outils dédiés à l’apprentissage profond en sciences humaines et sociales. L’accès est rendu possible à une grande masse d’archives, mais celle-ci est encore sous-explorée. Les outils développés intègrent des modèles adaptés aux différents types de sources et aux différents usages et besoins de la communauté des chercheurs et professionnels de la documentation. Le projet s’intègre dans l’environnement de recherche en lien avec d’autres projets existants et vise à produire des modèles réutilisables ultérieurement pour d’autres projets à venir.
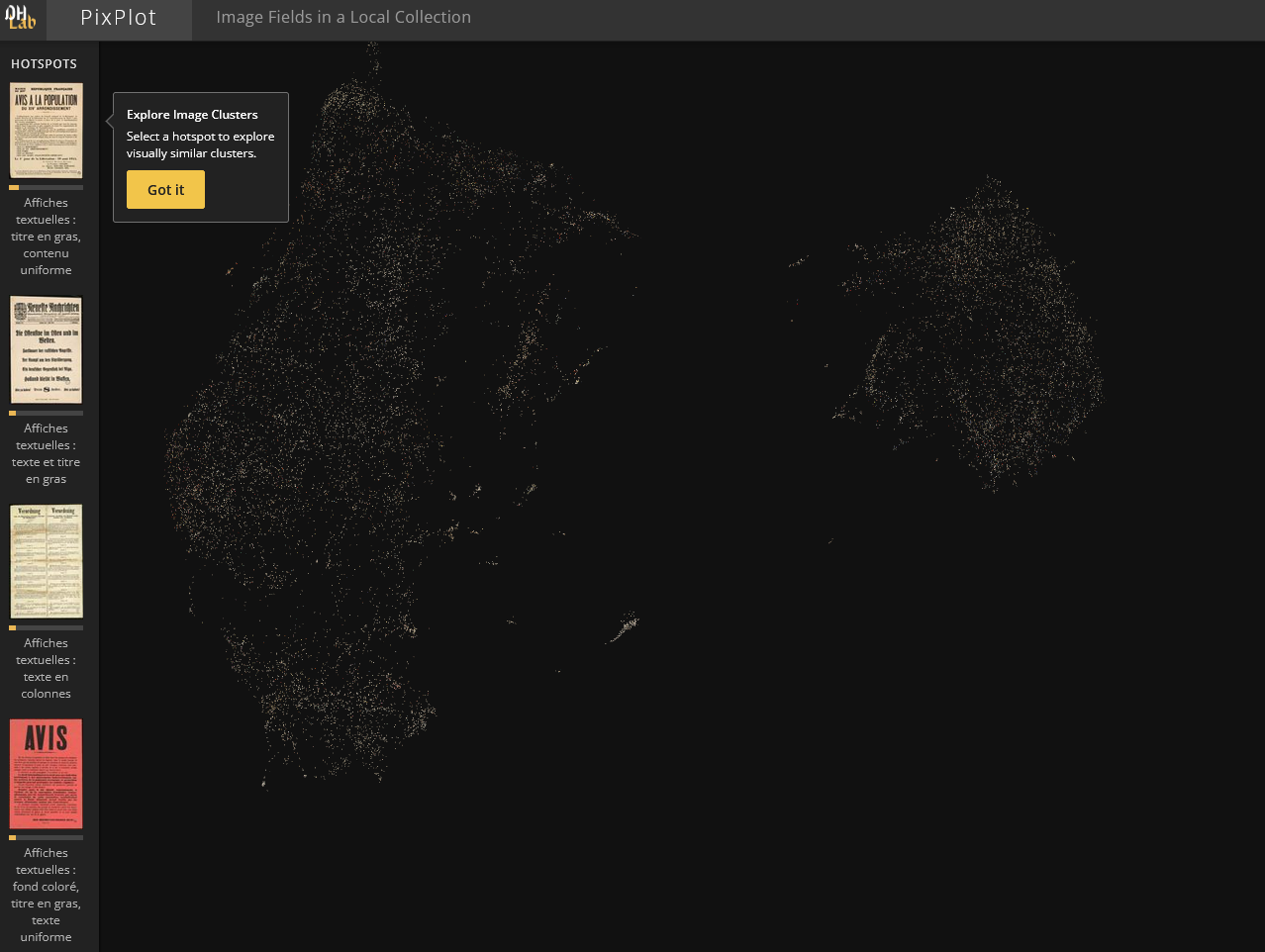
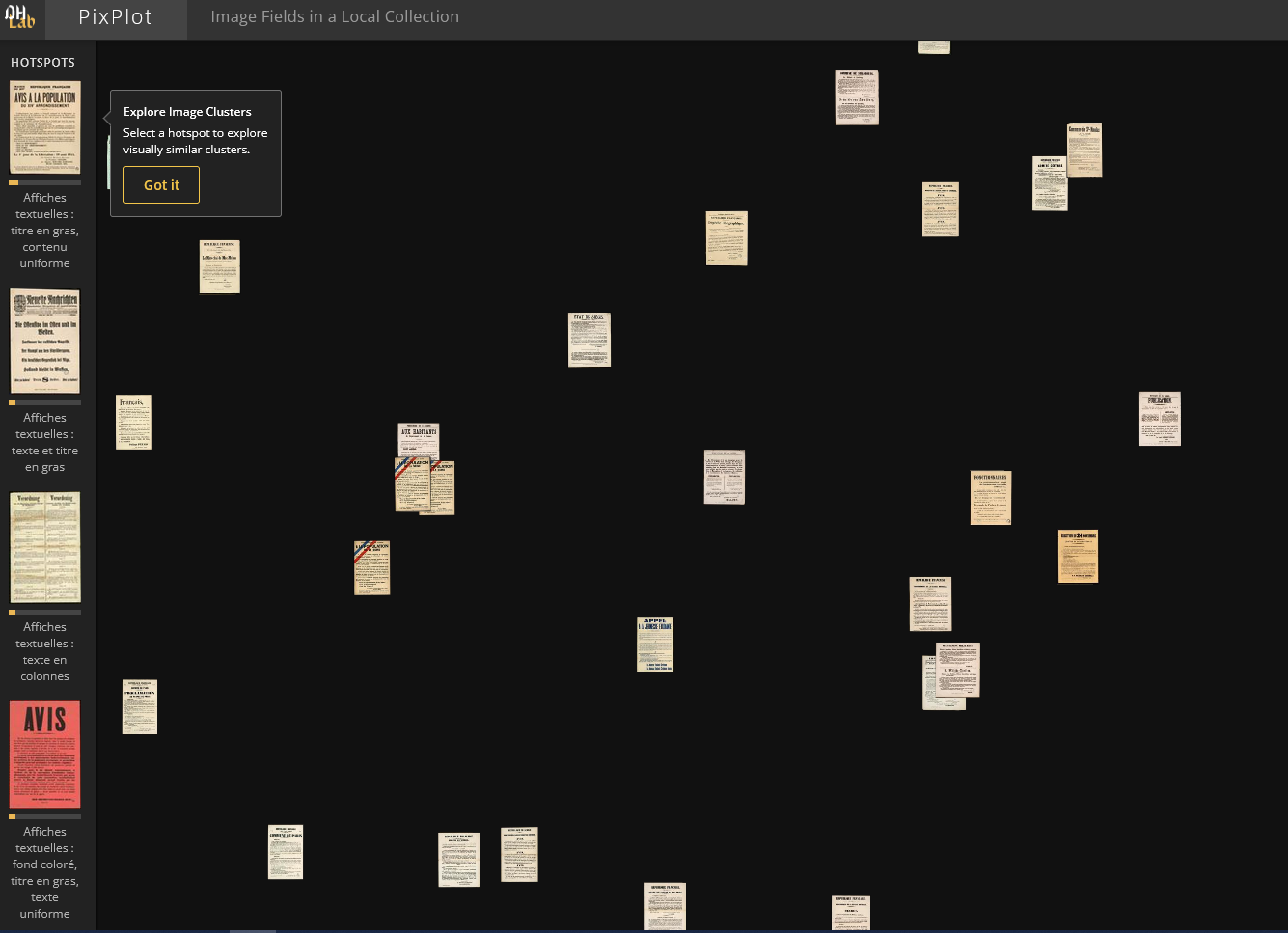
L’outil PixPlot a été utilisé pour classer les fichiers jpg suivant leur ressemble physique ; plus deux images sont proches, plus elles sont similaires. PixPlot génère des clusters, groupes thématiques cohérents d’images, dont il s’agit ensuite d’identifier la particularité commune.
Quel est ton apport sur le projet Ey-Con ?
Au sein du projet Eycon, je m’occupe de la collecte des données (photographies, albums et périodiques – numérisés ou non) avec les différentes institutions partenaires. L’étape cruciale de mon travail est celle de la création de l’architecture de ces données et de leurs métadonnées qu’il est nécessaire de normaliser. Les outils d’intelligence artificielle vont permettre d’enrichir les connaissances existantes à propos de ce corpus créé, je dois donc trouver un moyen de les intégrer. La structure finale de la base de données et du site web doit permettre – selon les standards IIIF en vigueur – d’accéder à une bibliothèque numérique complète, avec un moteur de recherche ainsi qu’à des visualisations graphiques et cartographiques que j’aurai créées grâce à la base de données.
Est-ce que ce type de projet s’inscrit dans les Humanités Numériques et quel sens donnerais-tu à ce terme ?
Selon moi, ce projet s’inscrit profondément dans les thématiques propres au Humanités numériques. Celles-ci couvrent un champ de disciplines propres aux humanités, auxquelles on ajoute une perspective et l’utilisation d’outils numériques. Ainsi, il est possible d’utiliser, voire même de créer des outils pour aider à l’étude de corpus et permettre de nouvelles analyses impossibles à l’œil nu. Il ne s’agit en aucun cas de détériorer une analyse scientifique humaine, mais de permettre de créer de nouveaux canaux d’entrées dans les documents, et de permettre l’étude à de larges échelles. Le développement de l’intelligence artificielle, notamment, ouvre des opportunités remarquables. Néanmoins, une perspective scientifique – dans le cas du projet Eycon, historique – est indispensable pour interpréter les résultats.
Est-ce qu’il y a un langage ou un outil que tu affectionnes particulièrement ?
J’ai personnellement appris à coder en Python qui est particulièrement utile pour l’étude de grandes bases de données et qui permet de faire un grand nombre de choses, assez facilement ! Actuellement, je crée par exemple des fiches bibliographiques de métadonnées des photographies du corpus d’Eycon automatiquement grâce à des scripts de code que j’écris. Des outils très utiles à la recherche aussi sont ceux de l’étude des textes: identifier automatiquement tous les lieux de tout un corpus de texte par exemple, permet d’effectuer des cartographies automatiques avec des milliers de lieux, et ce très rapidement.
Qu’est-ce que tu envisages pour la suite de ta carrière ?
Travailler sur des projets d’Humanités numériques me plaît énormément, j’aimerais donc beaucoup pouvoir continuer. L’avantage est que les projets étant innovants, une réflexion constante est nécessaire sur nos pratiques – notamment concernant le passage au numérique, ce qui ne rend absolument aucun travail mécanique ou répétitif. Les avancées de l’IA comme les deux projets auxquels je participe me portent à continuer dans ce domaine dans le but de nourrir une réflexion historique.
